
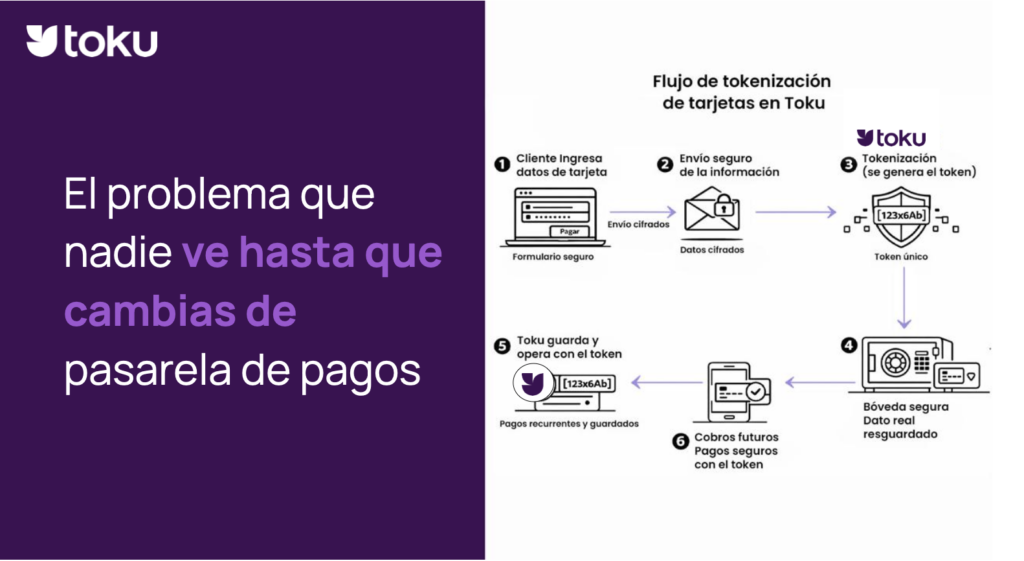
La tokenización es un proceso fundamental en el ámbito de la informática, especialmente en el procesamiento del lenguaje natural (PNL) y el análisis de datos. Se trata de un método que convierte la información en tokens, unidades discretas que representan elementos como palabras, números o caracteres especiales. Estos tokens son la base para analizar, procesar y comprender la información de manera eficiente.
La tokenización es un paso esencial en la cadena de procesamiento de datos textuales. Permite convertir datos complejos en unidades más manejables que facilitan la extracción de información, la búsqueda de patrones, la traducción y la clasificación de datos. En este artículo, profundizaremos en el concepto de la tokenización, explorando sus diferentes métodos, aplicaciones y ejemplos para que puedas comprender su importancia en el mundo digital actual.
¿Qué es la tokenización?
En términos simples, la tokenización es la división de un flujo de texto en unidades individuales llamadas tokens. Estos tokens pueden ser palabras, números, símbolos o cualquier otra secuencia de caracteres que tenga un significado específico en el contexto del análisis de datos.
Imagina que tienes una frase como «El perro corre rápido por el parque». La tokenización de esta frase produciría los siguientes tokens:
- «El»
- «perro»
- «corre»
- «rápido»
- «por»
- «el»
- «parque»
Cada uno de estos tokens representa una unidad independiente de información que puede ser analizada, procesada o almacenada de manera individual.
Métodos de tokenización
Existen diferentes métodos de tokenización que se utilizan en función del tipo de datos y el objetivo del análisis. Algunos de los métodos más comunes incluyen:
- Tokenización por espacio: Este es el método más simple y consiste en dividir el texto en tokens utilizando los espacios en blanco como separadores. Este método funciona bien para textos en idiomas con separación clara entre las palabras, como el inglés.
- Tokenización por carácter: Este método divide el texto en tokens basándose en cada carácter individual. Es útil para analizar lenguajes sin separación explícita entre palabras, como el chino o el japonés.
- Tokenización por subpalabra: Este método divide el texto en tokens que pueden ser subpalabras o morfemas, las unidades mínimas de significado en un idioma. Es útil para analizar palabras compuestas o palabras que pueden tener diferentes significados dependiendo del contexto.
- Tokenización basada en reglas: Este método utiliza reglas predefinidas para determinar los límites de los tokens. Las reglas pueden incluir información sobre la puntuación, el uso de mayúsculas y minúsculas, y la estructura de las palabras.
- Tokenización basada en aprendizaje automático: Este método utiliza algoritmos de aprendizaje automático para identificar los límites de los tokens a partir de un conjunto de datos de entrenamiento. Este método es más preciso que los métodos basados en reglas, pero requiere más datos y recursos computacionales.
Aplicaciones de la tokenización
La tokenización tiene numerosas aplicaciones en diversas áreas, incluyendo:
- Procesamiento del lenguaje natural (PNL): La tokenización es un paso fundamental en el PNL, ya que permite analizar la estructura gramatical y semántica del texto.
- Búsqueda de información: La tokenización se utiliza en los motores de búsqueda para indexar y recuperar documentos relevantes.
- Traducción automática: La tokenización permite dividir el texto en unidades que pueden ser traducidas de forma independiente.
- Análisis de sentimiento: La tokenización se utiliza para identificar palabras o frases que expresan emociones o sentimientos en el texto.
- Análisis de redes sociales: La tokenización se utiliza para analizar el contenido de las redes sociales y entender las interacciones entre los usuarios.
- Análisis de datos de mercado: La tokenización se utiliza para analizar datos de mercado y comprender las tendencias del consumidor.
Ejemplos de tokenización
Para ilustrar mejor el concepto de tokenización, aquí se presentan algunos ejemplos:
- Ejemplo 1:
- Texto: «La capital de España es Madrid»
- Tokens: «La», «capital», «de», «España», «es», «Madrid»
- Ejemplo 2:
- Texto: «El número de teléfono es 123-456-7890»
- Tokens: «El», «número», «de», «teléfono», «es», «123-456-7890»
- Ejemplo 3:
- Texto: «¡Hola! ¿Cómo estás?»
- Tokens: «¡Hola!», «¿», «Cómo», «estás», «?»
Conclusiones
La tokenización es un proceso esencial para el análisis de datos textuales. Permite convertir información compleja en unidades más manejables que facilitan la extracción de información, la búsqueda de patrones, la traducción y la clasificación de datos. La comprensión de los diferentes métodos y aplicaciones de la tokenización es crucial para aprovechar al máximo las herramientas de análisis de datos y el procesamiento del lenguaje natural en el mundo digital actual.

